
Socket套接字(网络编程万字总结-附代码)
文章目录
- 前言
- 一、概念
- 二、分类(三类)
-
- 2.1 流套接字:使用传输层TCP协议
- 2.2 数据报套接字:使用传输层UDP协议
- 2.3 原始套接字
- 三、UDP数据报套接字编程
-
- 3.1 Java数据报套接字通信模型
- 3.2 DatagramSocket API
-
- 3.2.1 ` DatagramSocket` 构造方法:
- 3.2.2 ` DatagramSocket` 普通方法(属于DatagramSocket类):
- 3.3 DatagramPacket API
-
- 3.3.1 ` DatagramPacket ` 构造方法:
- 3.3.2 ` DatagramPacket` 普通方法:
- 3.4 InetSocketAddress API
- 3.5 代码示例(有请求和相应)
- 四、TCP数据报套接字编程
-
- 4.1 Java流套接字通信模型
- 4.2 ServerSocket API
-
- 4.2.1 ` ServerSocket` 构造方法:
- 4.2. ` ServerSocket` 普通方法
- 4.3 Socket API
-
- 4.3.1 ` Socket` 构造方法:
- 4.3.2 ` Socket` 普通方法:
- 4.4 TCP中的长短连接
- 4.5 代码示例(短连接)
- 五、 关于输入流和输出流的使用
-
- 5.1 关于输入流的使用:
- 5.2 关于输出流的使用:
- 六、面向数据报文VS面向字节流
- 总结
前言
一、概念
Socket是站在应用层,做网络编程很重要的一个概念
传输层、网络层、数据链路层、物理层 都是通过OS+硬件来提供服务的,而应用层要享受OS提供的网络服务,需要通过OS提供的服务窗口(Socket)来享受服务。
拓展:
OS原生的提供的系统调用(Linux上的网络编程):
int fd = socket(); setsocketopt(fd,TCP or UDP) 二、分类(三类)
Socket套接字主要针对传输层协议划分为如下三类:
2.1 流套接字:使用传输层TCP协议
TCP,即Transmission Control Protocol(传输控制协议),传输层协议。
以下为TCP的特点:
- 有连接
- 可靠传输
- 面向字节流
- 有接收缓冲区,也有发送缓冲区
- 大小不限
对于字节流来说,可以简单的理解为,传输数据是基于IO流,流式数据的特征就是在IO流没有关闭的情况下,是无边界的数据,可以多次发送,也可以分开多次接收。
2.2 数据报套接字:使用传输层UDP协议
UDP,即User Datagram Protocol(用户数据报协议),传输层协议。
以下为UDP的特点:
- 无连接
- 不可靠传输
- 面向数据报
- 有接收缓冲区,无发送缓冲区
- 大小受限:一次最多传输64k
对于数据报来说,可以简单的理解为,传输数据是一块一块的,发送一块数据假如100个字节,必须一次发送,接收也必须一次接收100个字节,而不能分100次,每次接收1个字节。
2.3 原始套接字
原始套接字用于自定义传输层协议,用于读写内核没有处理的IP协议数据。
三、UDP数据报套接字编程
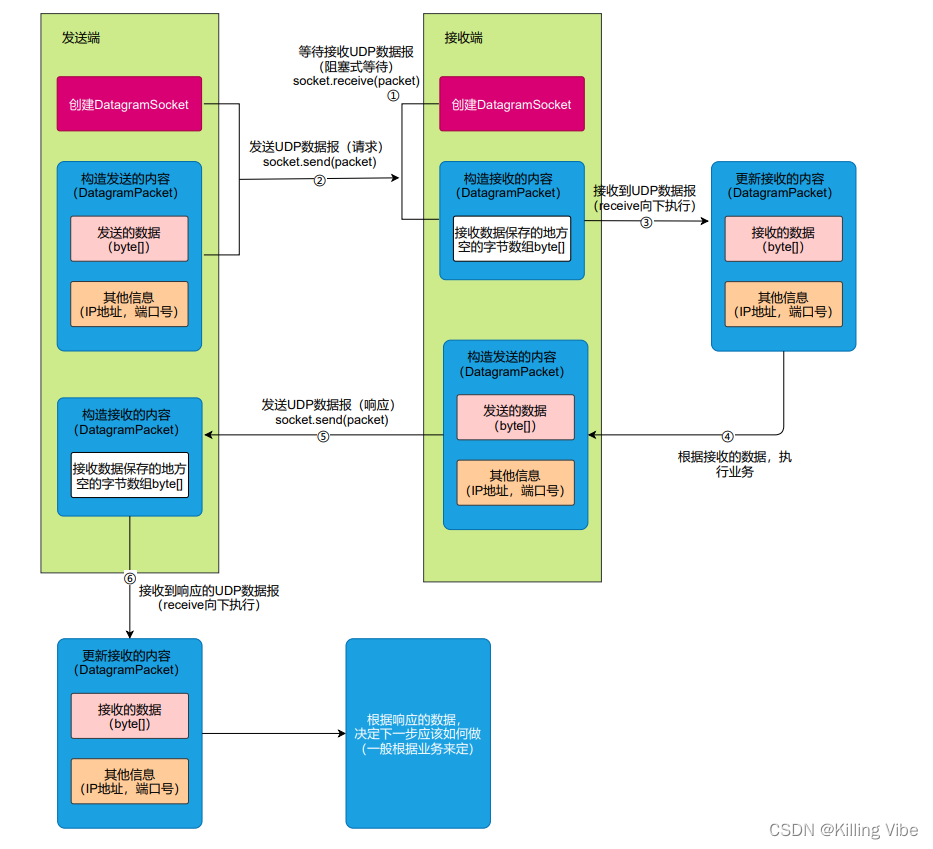
3.1 Java数据报套接字通信模型
java中使用UDP协议通信,主要基于 DatagramSocket 类来创建数据报套接字,并使用
DatagramPacket 作为发送或接收的UDP数据报。对于一次发送及接收UDP数据报的流程如下:
3.2 DatagramSocket API
3.2.1 DatagramSocket 构造方法:

注意:
-
UDP服务器(Server):采用一个固定端口,方便客户端(Client)进行通信;
使用DatagramSocket(int port),就可以绑定到本机指定的端口,此方法可能有错误风险,提示该端口已经被其他进程占用。 -
UDP客户端(Client):不需要采用固定端口(也可以用固定端口),采用随机端口;
使用DatagramSocket(),绑定到本机任意一个随机端口
3.2.2 DatagramSocket 普通方法(属于DatagramSocket类):

注意:
-
一旦通信双方逻辑意义上有了通信线路,双方地位就平等了(谁都可以作为发送方和接收方)
-
发送方调用的就是
send()方法,接收方调用的就是receive()方法 -
通信结束后,双方都应该调用
close()方法进行资源回收
3.3 DatagramPacket API
这个类就是定义的报文包:通信过程中的数据抽象
可以理解为:发送/接受的一个信封(五元组+信件)
3.3.1 DatagramPacket 构造方法:
 注意:
注意:
- 作为接收方:只需要提供存放接受数据的位置(byte[] buf + int length)
- 作为发送方:需要有要发送的数据(byte[] buf +int offset +int length),要发送给谁(远端ip+远端port)
3.3.2 DatagramPacket 普通方法:
 注意:
注意:
- 一般给服务器使用的是
getAddress()方法和getPort()方法,用来获取客户端的ip地址和端口号port - 一般给接收者(可以是服务器也可是客户端)使用的是
getData(),用来拿到“信”(对方进程发送的应用层数据)
3.4 InetSocketAddress API
InetSocketAddress ( SocketAddress 的子类 )构造方法:

3.5 代码示例(有请求和相应)
以下仅展示部分代码,完整代码可以看博主的gitee仓库:
网络开发代码
UDP客户端:
public class UserInputLoopClient { public static void main(String[] args) throws Exception { Scanner scanner = new Scanner(System.in); // 1. 创建 UDP socket Log.println("准备创建 UDP socket"); DatagramSocket socket = new DatagramSocket(); Log.println("UDP socket 创建结束"); System.out.print("请输入英文单词: "); while (scanner.hasNextLine()) { // 2. 发送请求 String engWord = scanner.nextLine(); Log.println("英文单词是: " + engWord); String request = engWord; byte[] bytes = request.getBytes("UTF-8"); // 手动构造服务器的地址 // 现在,服务器和客户端在同一台主机上,所以,使用 127.0.0.1 (环回地址 loopback address) // 端口使用 TranslateServer.PORT(8888) InetAddress loopbackAddress = InetAddress.getLoopbackAddress(); InetAddress remoteAddress = Inet4Address.getByName("182.254.132.183"); DatagramPacket sentPacket = new DatagramPacket( bytes, 0, bytes.length, // 要发送的数据 remoteAddress, TranslateServer.PORT // 对方的 ip + port ); Log.println("准备发送请求"); socket.send(sentPacket); Log.println("请求发送结束"); // 3. 接收响应 byte[] buf = new byte[1024]; DatagramPacket receivedPacket = new DatagramPacket(buf, buf.length); Log.println("准备接收响应"); socket.receive(receivedPacket); Log.println("响应接收接收"); byte[] data = receivedPacket.getData(); int len = receivedPacket.getLength(); String response = new String(data, 0, len, "UTF-8"); String chiWord = response; Log.println("翻译结果: " + chiWord); System.out.print("请输入英文单词: "); } // 4. 关闭 socket socket.close(); } } UDP服务端:
// 提供翻译的服务器 public class TranslateServer { // 公开的 ip 地址:就看进程工作在哪个 ip 上 // 公开的 port:需要程序中指定 public static final int PORT = 8888; // SocketException -> IOException -> Exception public static void main(String[] args) throws Exception { Log.println("准备进行字典的初始化"); initMap(); Log.println("完成字典的初始化"); Log.println("准备创建 UDP socket,端口是 " + PORT); DatagramSocket socket = new DatagramSocket(PORT); Log.println("UDP socket 创建成功"); // 作为服务器,是被动的,循环的进行请求-响应周期的处理 // 等待请求,处理并发送响应,直到永远 while (true) { // 1. 接收请求 byte[] buf = new byte[1024]; // 1024 代表我们最大接收的数据大小(字节) DatagramPacket receivedPacket = new DatagramPacket(buf, buf.length); Log.println("准备好接收 DatagramPacket,最大大小为: " + buf.length); Log.println("开始接收请求"); socket.receive(receivedPacket); // 这个方法就会阻塞(程序执行到这里就不动了,直到有客户发来请求,才能继续) Log.println("接收到请求"); // 2. 一旦走到此处,一定是接收到请求了,拆信 // 拆出对方的 ip 地址 InetAddress address = receivedPacket.getAddress(); Log.println("对方的 IP 地址: " + address); // 拆出对方的端口 int port = receivedPacket.getPort(); Log.println("对方的 port: " + port); // 拆出对方的 ip 地址 + port SocketAddress socketAddress = receivedPacket.getSocketAddress(); Log.println("对象的完整地址: " + socketAddress); // 拆出对方发送过来的数据,其实这个 data 就是我们刚才定义的 buf 数组 byte[] data = receivedPacket.getData(); Log.println("接收到的对象的数据: " + Arrays.toString(data)); // 拆出接收到的数据的大小(字节) int length = receivedPacket.getLength(); Log.println("接收的数据大小(字节):" + length); // 3. 解析请求 :意味着我们需要定义自己的应用层协议 // 首先,做字符集解码 byte[] -> String String request = new String(data, 0, length, "UTF-8"); // 这个按照我们的应用层协议 String engWord = request; Log.println("请求(英文单词):" + engWord); // 4. 执行业务(翻译服务),不是我们本次演示的重点 String chiWord = translate(engWord); Log.println("翻译后的结果:" + chiWord); // 5. 按照应用层协议,封装响应 String response = chiWord; // 进行字符集编码 String -> byte[] byte[] sendBuf = response.getBytes("UTF-8"); // 6. 发送响应 // 作为发送方需要提供 DatagramPacket sentPacket = new DatagramPacket( sendBuf, 0, sendBuf.length, // 要发送的数据 socketAddress // 从请求信封中拆出来的对象的地址(ip + port) ); Log.println("准备好发送 DatagramPacket 并发送"); socket.send(sentPacket); Log.println("发送成功"); // 7. 本次请求-响应周期完成,继续下一次请求-响应周期 } // socket.close(); // 由于我们是死循环,这里永远不会走到 } private static final HashMap<String, String> map = new HashMap<>(); private static void initMap() { map.put("apple", "苹果"); map.put("pear", "梨"); map.put("orange", "橙子"); } private static String translate(String engWord) { String chiWord = map.getOrDefault(engWord, "查无此单词"); return chiWord; } } 自定义的日志类(记得导入此类):
public class Log { public static void println(Object o) { LocalDateTime localDateTime = LocalDateTime.now(ZoneId.of("Asia/Shanghai")); DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"); String now = formatter.format(localDateTime); String message = now + ": " + (o == null ? "null" : o.toString()); System.out.println(message); } public static void main(String[] args) { println(1); } } 四、TCP数据报套接字编程
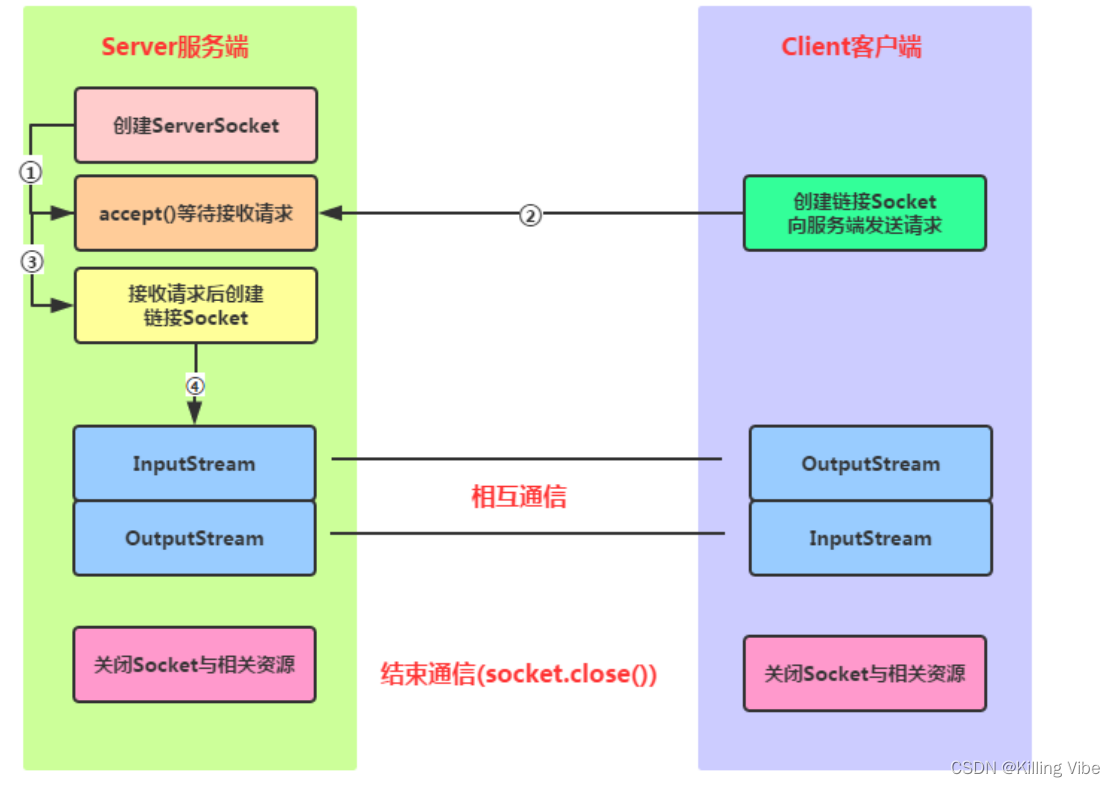
4.1 Java流套接字通信模型
4.2 ServerSocket API
4.2.1 ServerSocket 构造方法:
 服务器使用的TCP Socket对象(传入的端口,就是要公开的端口,一般称为监听(listen)端口)
服务器使用的TCP Socket对象(传入的端口,就是要公开的端口,一般称为监听(listen)端口)
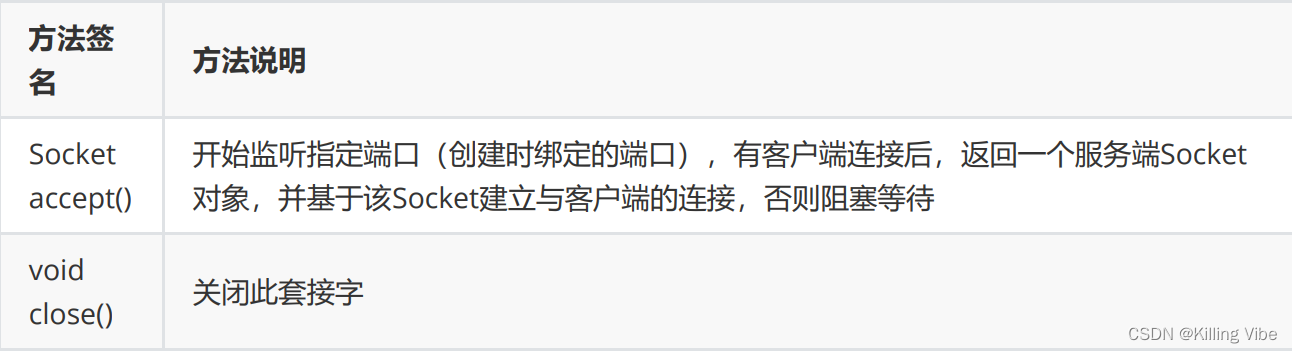
4.2. ServerSocket 普通方法
 注意:
注意:
-
accept:接起电话(服务器是电话铃响的这一方)
-
Socket对象:建立起的连接

-
close:挂电话(谁都可以挂)
4.3 Socket API
不管是客户端还是服务端Socket,都是双方建立连接以后,保存的对端信息,及用来与对方收发数据的。
4.3.1 Socket 构造方法:
 注意:
注意:
- 服务器的Socket对象是从accept()中获取到的,所以,只有客户端的Socket对象需要手动实例化出来,这个构造方法是给客户端使用,传入服务器的ip+port
- 一旦socket对象拿到(双方是同时拿到的),双方就地位平等了,只区分发送方和接收方即可
4.3.2 Socket 普通方法:
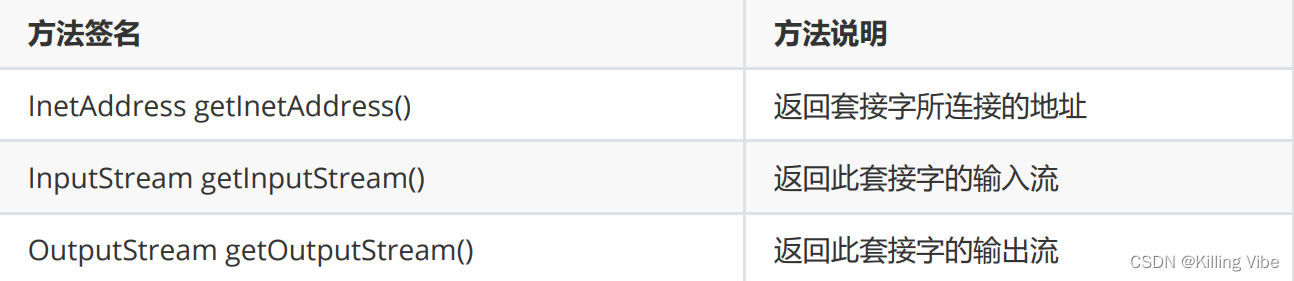 注意:
注意:
- 输入流:站在进程角度,背后对象就是网卡,网卡抽象出来的TCP连接,所以是给接收方使用
- 输出流:同理,所以是给发送方使用
4.4 TCP中的长短连接
TCP发送数据时,需要先建立连接,什么时候关闭连接就决定是短连接还是长连接:
- 短连接:每次接收到数据并返回响应后,都关闭连接,即是短连接。也就是说,短连接只能一次收发数据。
- 长连接:不关闭连接,一直保持连接状态,双方不停的收发数据,即是长连接。也就是说,长连接可以多次收发数据。
对比以上长短连接,两者区别如下:
- 建立连接、关闭连接的耗时:短连接每次请求、响应都需要建立连接,关闭连接;而长连接只需要第一次建立连接,之后的请求、响应都可以直接传输。相对来说建立连接,关闭连接也是要耗时的,长连接效率更高。
- 主动发送请求不同:短连接一般是客户端主动向服务端发送请求;而长连接可以是客户端主动发送请求,也可以是服务端主动发。
- 两者的使用场景有不同:短连接适用于客户端请求频率不高的场景,如浏览网页等。长连接适用于客户端与服务端通信频繁的场景,如聊天室,实时游戏等。
扩展了解:
基于BIO(同步阻塞IO)的长连接会一直占用系统资源。对于并发要求很高的服务端系统来说,这样的消耗是不能承受的。
实际应用时,服务端一般是基于NIO(即同步非阻塞IO)来实现长连接,性能可以极大的提升。
现在还遗留一个问题:
如果同时多个长连接客户端,连接该服务器,能否正常处理?
需要在IDEA配置客户端支持同时运行多个实例!
- 短连接客户端 <–> 短连接服务器 支持同时在线
- 短连接客户端 <-> 长连接服务器 支持同时在线
- 长连接客户端 <-> 长连接服务器 不支持同时在线
所以可以使用多线程解决长连接客户端不支持同时在线的问题:
将任务专门交给其他线程来处理,主线程只负责接受socket。
4.5 代码示例(短连接)
这里仅演示短连接,长连接和多线程在博主的个人仓库下:
网络开发代码
TCP服务端:
public class TranslateServerShortConnection { public static final int PORT = 8888; public static void main(String[] args) throws Exception { Log.println("启动短连接版本的 TCP 服务器"); initMap(); ServerSocket serverSocket = new ServerSocket(PORT); while (true) { // 接电话 Log.println("等待对方来连接"); Socket socket = serverSocket.accept(); Log.println("有客户端连接上来了"); // 对方信息: InetAddress inetAddress = socket.getInetAddress(); // ip Log.println("对方的 ip: " + inetAddress); int port = socket.getPort(); // port Log.println("对方的 port: " + port); SocketAddress remoteSocketAddress = socket.getRemoteSocketAddress(); // ip + port Log.println("对方的 ip + port: " + remoteSocketAddress); // 读取请求 InputStream inputStream = socket.getInputStream(); Scanner scanner = new Scanner(inputStream, "UTF-8"); String request = scanner.nextLine(); // nextLine() 就会去掉换行符 String engWord = request; Log.println("英文: " + engWord); // 翻译 String chiWord = translate(engWord); Log.println("中文: " + chiWord); // 发送响应 String response = chiWord; // TODO: 响应的单词中是没有 /r/n OutputStream outputStream = socket.getOutputStream(); OutputStreamWriter outputStreamWriter = new OutputStreamWriter(outputStream, "UTF-8"); PrintWriter writer = new PrintWriter(outputStreamWriter); Log.println("准备发送"); writer.printf("%s/r/n", response); writer.flush(); Log.println("发送成功"); // 挂掉电话 socket.close(); Log.println("挂断电话"); } // serverSocket.close(); } private static final HashMap<String, String> map = new HashMap<>(); private static void initMap() { map.put("apple", "苹果"); map.put("pear", "梨"); map.put("orange", "橙子"); } private static String translate(String engWord) { String chiWord = map.getOrDefault(engWord, "查无此单词"); return chiWord; } } TCP客户端:
public class UserInputLoopShortConnectionClient { public static void main(String[] args) throws Exception { Scanner userInputScanner = new Scanner(System.in); while (true) { // 这里做了一个假设:1)用户肯定有输入 2)用户一行一定只输入一个单词(没有空格) System.out.print("请输入英文单词: "); if (!userInputScanner.hasNextLine()) { break; } String engWord = userInputScanner.nextLine(); // 直接创建 Socket,使用服务器 IP + PORT Log.println("准备创建 socket(TCP 连接)"); Socket socket = new Socket("127.0.0.1", TranslateServerShortConnection.PORT); Log.println("socket(TCP 连接) 创建成功"); // 发送请求 Log.println("英文: " + engWord); String request = engWord + "/r/n"; OutputStream os = socket.getOutputStream(); OutputStreamWriter osWriter = new OutputStreamWriter(os, "UTF-8"); PrintWriter writer = new PrintWriter(osWriter); Log.println("发送请求中"); writer.print(request); writer.flush(); Log.println("请求发送成功"); // 等待接受响应 InputStream is = socket.getInputStream(); Scanner socketScanner = new Scanner(is, "UTF-8"); // 由于我们的响应一定是一行,所以使用 nextLine() 进行读取即可 // nextLine() 返回的数据中,会自动把 /r/n 去掉 // TODO: 没有做 hasNextLine() 的判断 Log.println("准备读取响应"); String chiWord = socketScanner.nextLine(); Log.println("中文: " + chiWord); socket.close(); } } } 五、 关于输入流和输出流的使用
5.1 关于输入流的使用:
- 如果直接进行二进制读取
byte[] buf = new byte[1024]; int n = inputStream.read(buf); - 如果读取文本数据,建议直接使用Scanner封装InputStream后再使用
Scanner S = new Scanner(inputStream,"UTF-8"); s.nextLine() ... s.hasNextLine() 5.2 关于输出流的使用:
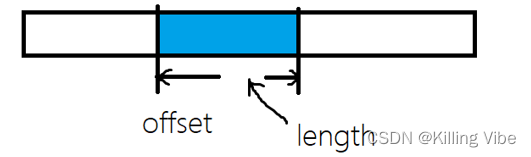
- 如果直接进行二进制输出
outputStream.write(buf,offset,length) - 如果是文本输出,建议OutputStream -> OutputStreamWriter -> PrintWriter
OutputStreamWriter osWriter = new OutputStreamWriter(outputStream,"UTF-8"); PrintWriter writer = new PrintWriter(osWriter); writer.println(...); writer.print(...); writer.printf(format,...); 重要:不要忘记刷新缓冲区,否则数据可能无法到达对方!!!
outputStream.flush(); //writer.flush(); 六、面向数据报文VS面向字节流
举个栗子:


总结
关于端口被占用的问题:
如果一个进程A已经绑定了一个端口,再启动一个进程B绑定该端口,就会报错,这种情况也叫端口被占用。对于java进程来说,端口被占用的常见报错信息如下:

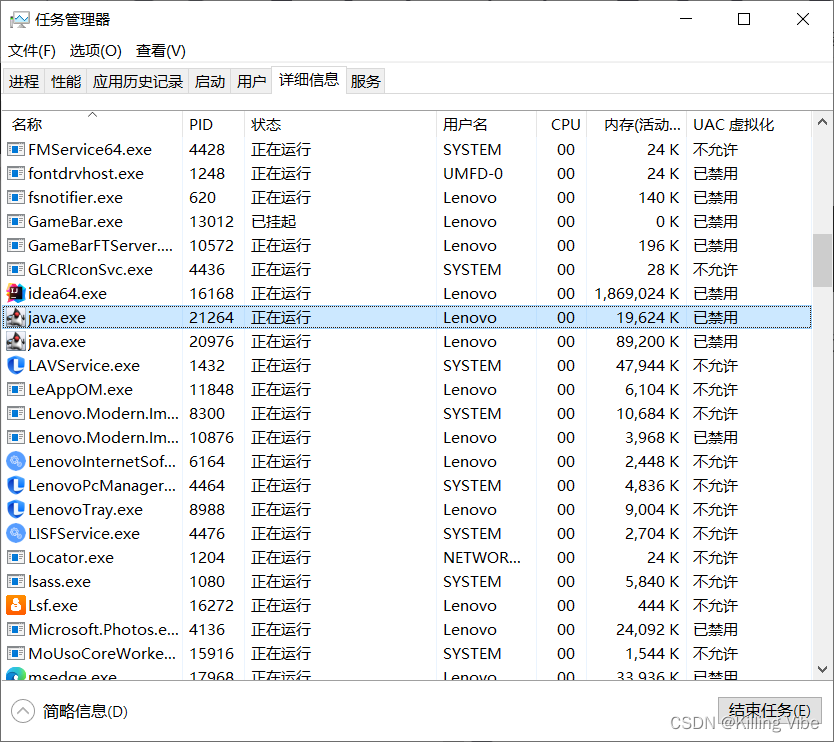
此时需要检查进程B绑定的是哪个端口,再查看该端口被哪个进程占用。以下为通过端口号查进程的方式:
-
在cmd输入 netstat -ano | findstr 端口号 ,则可以显示对应进程的pid。如以下命令显
示了8888进程的pid

-
在任务管理器中,通过pid查找进程
解决端口被占用的问题:
- 如果进程没啥用,就可以把进程杀掉
- 如果进程不确定,可以换个端口使用
共有 0 条评论